
8. Do your customers cluster?
Clustering your customer data can unlock powerful insights.

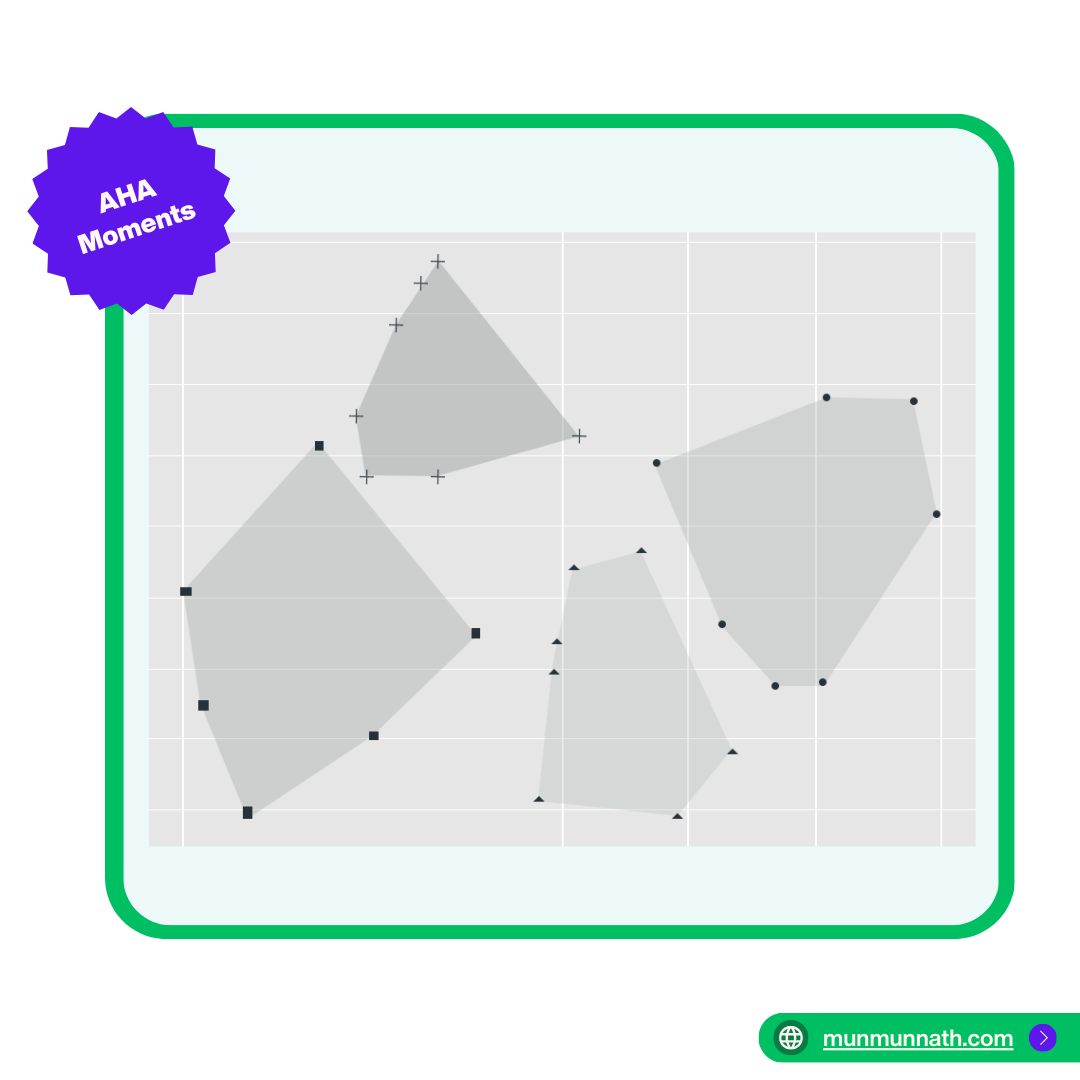
Cluster Analysis is a frequently used analytical method for identifying meaningful segments in customer data. It helps marketers to:
Divide customers into distinct groups based on similarities and differences in their behaviors, preferences, or demographics.
Personalize marketing campaigns to target specific clusters.
Provide insights into cluster-specific preferences, guiding product development efforts.
Can help to identify high-value segments with potential for long-term relationship and profitability
Manage data better by segregating valuable information from redundant data that can be discarded.


Here are a few key examples of business situations where clustering can be applied -
A retail bank collects the following information on customer salary accounts -
Salary credits
No of Transactions
They can then feed these variables into a clustering algorithm to identify the following clusters:
Cluster 1: Low Income, low spenders
Cluster 2:High Income, low spenders
Cluster 3: Low-income, high spenders
Cluster 4: High-income, high-spenders
The bank can then send personalized offers such as -
Cluster 1: Micro-Insurance
Cluster 2: Cash-back on transactions
Cluster 3: Personal Loan
Cluster 4: Pre-approved Credit Card

A streaming service like Netflix may collect the following data about individuals:
Minutes watched per day
Number of unique shows viewed per month
Using these metrics, Netflix may identify high-usage and low-usage clusters to spend their advertising dollars more effectively.
They can use clustering to group their content based on their title, genre, cast, and plot to group them into similar categories to fuel their personalized recommendations.

Professional sports teams often use clustering to identify players who are similar to each other. They may collect the following information about players:
Points scored per game.
Duration of their play
Similar clusters of players may then perform specific drills based on their strengths and weaknesses.

Actuaries at health insurance can use cluster analysis to identify consumers who use their health insurance in specific ways. They may collect the following information about households:
Total number of doctor visits per year
Total household size
Total number of chronic conditions per household
Average age of household members
They can then set monthly premiums based on how often they expect households in specific clusters to use their insurance.
Many other applications range from identification of fake news, spam, and content aggregation to credit scoring, portfolio selection, fraud detection, etc.
How is clustering done?
This is an ‘unsupervised machine-learning’ technique, meaning the algorithms learn patterns and structures from input data without explicit guidance or labeled examples. The goal is to group the data so that observations within each cluster are similar while observations in different clusters are quite different.
One common method is K-means clustering. Imagine having a basket of vegetables like carrots, cucumbers, and tomatoes. Using the k-means algorithm is like sorting them into separate boxes based on color, size, and shape similarities. You keep adjusting the boxes until each contains the most common vegetables, forming distinct groups.
These clustering techniques require using programs like statistical software such as R and Python and data visualization tools such as Tableau or Power BI.
Several other tools make clustering more accessible to marketers, such as -
Many CRM platforms include built-in segmentation and clustering features to help marketers understand and target customer segments. One example is the feature of Cluster transformation in Salesforce Data Pipelines.

Some marketing automation tools provide clustering functionalities to segment audiences and personalize marketing campaigns based on these segments.
Google Analytics offers features like audience segmentation and cohort analysis, which can be used for clustering and understanding website user behavior.


These tools vary in complexity and capability, so marketers can choose based on their specific needs and expertise.
References:
https://www.statology.org/cluster-analysis-real-life-examples/
https://help.salesforce.com/s/articleView?id=sf.bi_integrate_recipe_transformation_cluster.htm&type=5
https://medium.com/ibm-data-ai/risk-based-customer-segmentation-within-banking-6109b1104f20
https://medium.com/nerd-for-tech/clustering-nba-player-using-k-means-7b568830edfd
https://www.andreaperlato.com/mlpost/customer-segmentation/
